DSPM and Data Discovery: Finding and Classifying Sensitive Data at Scale

February 26, 2026
•
1 min
Proprietary data is the definitive differentiator in the age of AI. Models can be replicated, infrastructure can be rented, and tools can be replaced. What cannot be easily reproduced is institutional knowledge, customer insight, and strategic intent found in enterprise data. This data must be continuously identified, deeply understood, and actively protected as it changes state, location, and context.
This fluid state of data has fundamentally reshaped how organizations think about data security posture management (DSPM). DSPM data discovery is no longer a static inventory exercise or a compliance-driven scan. It is the foundation for continuous visibility, accurate risk prioritization, and enforceable control in environments where data is fragmented, constantly moving, and increasingly entangled with generative and agentic AI workflows.
To meet this reality, a modern DSPM must innovate how data is discovered and classified. It must move beyond snapshots and labels toward continuous, context-aware understanding of how sensitive data is created, used, transformed, and exposed across the enterprise. This is why DSPM data discovery and classification have become foundational to modern data security.
What Is DSPM Data Discovery?
DSPM data discovery is the continuous process of identifying, mapping, and monitoring sensitive data across cloud, SaaS, endpoints, on-prem systems, and AI tools. Unlike traditional discovery, it operates in real time and incorporates context such as usage, access, and data lineage to prioritize risk.
Why Data Discovery Is the Foundation of DSPM
Every DSPM program starts with a simple question that is deceptively hard to answer:
Where is our sensitive data?
In modern enterprises, data no longer lives in a handful of well-defined repositories. It exists across cloud infrastructure, SaaS platforms, endpoints, on-prem systems, and now AI tools. It is copied, transformed, summarized, and embedded into workflows that were never designed to carry sensitive information, often as part of normal business operations.
Without modern DSPM, organizations struggle to:
- Discover all of their data across environments and ownership boundaries
- Identify which data carries the highest business and security risk
- Reduce and right-size access as data spreads and permissions drift
- Contain critical data as it is copied, shared, and consumed
Traditional discovery approaches cannot keep up with this reality. Periodic scans of known storage locations may provide a sense of control, but they fail to capture how data actually behaves in day-to-day operations.
DSPM data discovery must focus on visibility across the full data lifecycle. It needs to answer not only where data lives today, but how it moves, how it is used, and how risk changes as context changes.
Modern DSPM Data Discovery vs. Traditional Data Discovery Tools
Many legacy tools approach data discovery as a compliance checkbox. They scan cloud storage, match patterns, and produce a report. This approach creates a dangerous illusion of coverage.
For example, many Cloud-native application protection platforms (CNAPPs) now advertise DSPM capabilities. In practice, these offerings typically fall short for two reasons. First, most stop at visibility and do not support meaningful prevention or control. Second, they focus almost exclusively on cloud IaaS. Data on endpoints, SaaS platforms, and on-prem systems is either ignored or treated as out of scope.
This matters because data is everywhere, not just on the cloud, and it's often fragmented and split between different parts of the environment.
Research from Cyberhaven Labs shows that more than 80% of data exfiltrated from modern organizations consists of fragments. These include portions of strategic plans, acquisition details, and customer information. They move quietly through browsers, chat tools, SaaS workflows, and cloud services, often without ever triggering file-based controls. These fragments increasingly fuel AI prompts, summaries, and automated workflows, often bypassing file-based controls entirely.
Traditional discovery methods were designed for a world where sensitive data was static and centralized. Modern DSPM must assume the opposite: data is dynamic, distributed, and continuously recombined.
How DSPM Performs Sensitive Data Discovery at Scale
Modern DSPM platforms are built around continuous, holistic discovery. Rather than relying on periodic scans, they maintain persistent awareness of data across environments and workflows.
Continuous, Cross-Environment Discovery
DSPM data discovery connects to every major data source across the organization, including:
- Cloud infrastructure such as Amazon Web Services, Microsoft Azure, and Google Cloud Platform
- SaaS applications used for collaboration, CRM, ticketing, and productivity
- On-prem databases and file shares supporting mission-critical systems
- Employee endpoints where data is created, modified, and shared
- Generative and Agentic AI tools accessed by employees
This approach enables true cloud data discovery alongside unstructured data discovery and structured data discovery across the full enterprise footprint.
Discovery must be continuous. Continuous discovery ensures that new data, shadow copies, and derived content are identified as soon as they appear, actively reducing risk and helping an organization improve its data security posture over time.
Explore how modern DSPM solutions should work to comprehensively protect organizations' mission-critical data.
Automated Data Classification in a DSPM Context
If discovery answers where data lives, classification answers what the data is and why it matters.
However, automated data classification is one of the most misunderstood aspects of DSPM. Many tools still rely on pattern matching and rigid rules. These approaches struggle with modern data for two reasons. First, unstructured data rarely follows predictable formats. Second, sensitivity is often determined by context, not content alone.
Modern DSPM platforms often use AI-driven classification to improve accuracy and reduce noise. This enables:
- Semantic understanding beyond regex and keyword matching
- Higher precision with fewer false positives
- Sensitivity assessment based on business context and usage
- Effective classification of unstructured and AI-generated content
This capability is critical as AI workflows consume and generate data in fragments. A single prompt may appear harmless in isolation, but when aggregated across systems, it can expose strategic intent or proprietary knowledge to the wrong user, amplifying risk and creating unintentional data leaks.
Powering Discovery and Classification With Context Graphs
Modern DSPM requires more than better classifiers. It requires a deeper understanding of how data, users, systems, and actions relate to one another. This is where context graphs become foundational.
A context graph models the relationships between data assets, users, applications, workflows, and business concepts. Instead of treating data as isolated objects, it connects them into a living structure that reflects how information is actually created, transformed, and used across the enterprise.
Within DSPM, context graphs enable AI systems to move beyond surface-level inspection and toward true semantic understanding. They essentially provide the connective tissue that allows DSPM platforms to:
- Move beyond surface indicators to determine why information carries risk, not just which rules it triggers
- Connect partial data signals across tools and platforms to surface real, business-relevant risk
- Automatically map how sensitive information propagates as it is reused, transformed, or incorporated into downstream workflows
- Keep classifications accurate over time as data, access, and usage patterns evolve
This graph-based understanding is especially critical in AI-driven environments. Prompts, summaries, and agent actions often contain only partial signals. Context graphs allow DSPM to reconstruct intent and sensitivity by analyzing how those fragments relate to known data sources, business processes, and user behavior. They turn fragments into insights.
Without context graphs, discovery remains shallow and classification remains brittle. With them, DSPM gains the foundation needed for continuous, adaptive understanding at scale.
Contextual Understanding: The Difference Between Labels and Insight
Classification alone cannot reveal risk. Two identical documents can represent very different security postures depending on how and where they are used.
Modern DSPM enriches discovered and classified data with context, including:
- Provenance: Whether data was internally created or sourced externally
- Exposure: Who can access it, including internal users, external collaborators, or the public
- Location: Endpoint, SaaS platform, cloud storage, or on-prem system
- Structure: Document, spreadsheet, database record, or raw text
- Management status: Whether the hosting system is managed or unmanaged
Context allows DSPM to differentiate meaningful risk from benign activity. An internal document stored on a managed laptop carries far less risk than the same document publicly shared from a SaaS platform.
This contextual understanding is essential for prioritization. Security teams are not suffering from a lack of information. They are struggling with a lack of clarity. DSPM data discovery must surface what matters most, not everything that exists, so security teams can take swift action when needed, not spend their time closing out false positives.
The Role of Data Lineage in Accurate Discovery and Classification
As data moves, it changes. It is copied, summarized, embedded, and transformed. Without understanding these transformations, discovery and classification quickly become stale.
Data lineage provides visibility into how sensitive information evolves across systems and workflows. It shows where data originated, how it was modified, and where it traveled next. This is especially important in AI-driven environments, where small fragments of data can be recombined into high-value outputs.
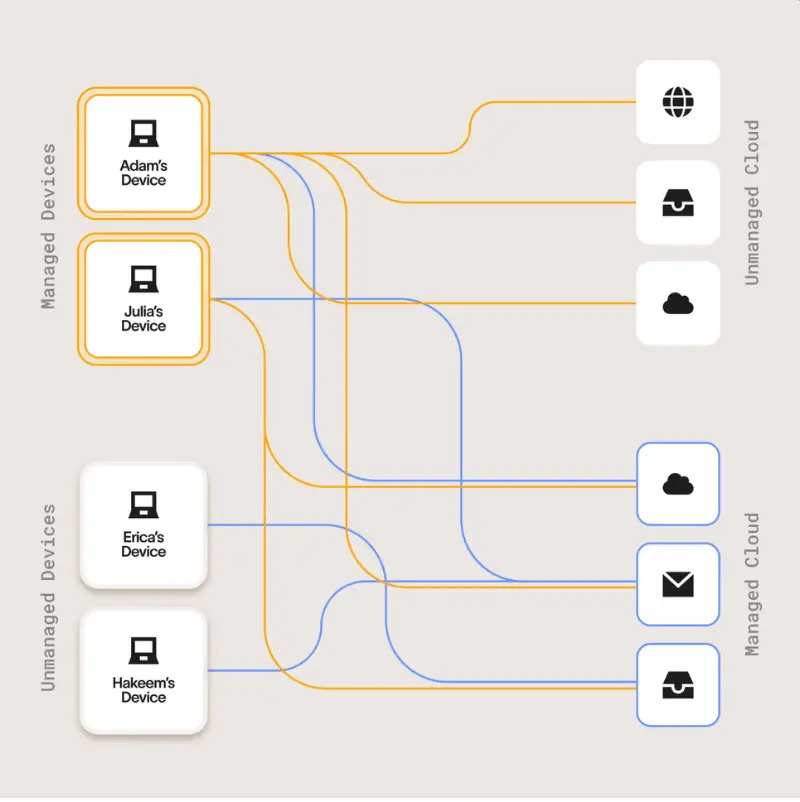
Lineage enables DSPM to:
- Track sensitive data as it moves across endpoints, SaaS, cloud, and AI tools
- Maintain accurate classification as data changes form and context
- Identify indirect exposure paths that static scans miss
- Support real-time decision-making as risk emerges
Without lineage, discovery becomes a snapshot. With lineage, it becomes a living model of the organization's data reality.
How AI and GenAI Are Changing Data Discovery and DSPM
Enterprise AI adoption amplifies every existing data security challenge. Even before autonomous agents gained ground within enterprise environments, generative AI workflows consume data through prompts, summaries, and automated actions. Each interaction may involve only a fragment of sensitive information, but the cumulative risk is substantial. Cyberhaven Labs found that the most eager organizations are seeing a 71.4% employee adoption rate of GenAI tools, with the number of tools utilized sprawling into the hundreds.
Agentic AI introduces additional complexity, and it's no longer a future problem. Around half of organizations see their internal developers utilizing AI coding agents, often embedded on endpoints, and over a quarter of enterprises have invested in agent-building platforms. Autonomous systems can access data, make decisions, and take actions across multiple platforms without direct human involvement. This accelerates data movement and reduces the window for detection.
In this environment, DSPM data discovery must operate in real time. It must recognize sensitive data not only at rest, but as it is used, transformed, and fed into AI systems. Static discovery models are fundamentally incompatible with AI-driven workflows.
Turning Discovery Into Action With Cyberhaven
DSPM data discovery is not an end state. Its value lies in enabling smarter decisions, tighter controls, and proactive protection.
By continuously discovering and classifying sensitive data across environments, security teams can reduce unnecessary exposure, right-size access, and protect the information that truly differentiates the business.
This is the approach taken by Cyberhaven, where DSPM is built on continuous discovery, contextual classification, and data lineage. By understanding how data moves and changes, organizations gain the clarity needed to secure modern workflows, including those powered by GenAI and agentic AI.
In an era where data is both the fuel for innovation and the primary source of risk, DSPM data discovery is no longer optional. It is the foundation of modern data security.
Take a deep dive into DSPM with our white paper, Next-Gen DSPM: Built for the AI-Driven Data World.
FAQ: DSPM and Data Discovery
What is DSPM data discovery?
DSPM data discovery is the continuous identification and monitoring of sensitive data across all environments, including cloud, SaaS, endpoints, and AI systems.
How is DSPM different from traditional data discovery tools?
Traditional tools rely on periodic scans and pattern matching. DSPM uses continuous monitoring, contextual analysis, and data lineage to understand how data is used and exposed in real time.
Why is data classification important in DSPM?
Data classification determines sensitivity and business impact, allowing organizations to prioritize risk and enforce appropriate controls.
What is sensitive data discovery?
Sensitive data discovery is the process of identifying data such as intellectual property, customer information, and financial records across an organization's environment.
How does AI impact data discovery?
AI increases the volume, speed, and fragmentation of data, making real-time discovery and context-aware classification essential.



.avif)
.avif)
