←
Back to Blog
Platform architecture
5/5/2022
-
XX
Minute Read
Protecting Data Requires a New Level of Resolution

At Cyberhaven, we enable organizations to directly protect the information that is the most valuable to them regardless of what the content is or how it is used. In short, organizations can now greatly extend their visibility into data risk and enforce real-time policies to mitigate that risk and prevent loss.
This is made possible by new advancements in data flow tracing and graph analysis that follow the full history and interaction of all data in the enterprise. Building a complete risk-based context for every piece of data in an enterprise is a profound undertaking, and in this series, we are taking a closer look at how this is done.
In our first installment of the series, we covered the basics of what graph analysis is and how it can be used to solve security problems in completely new ways. In Part 2, we will start to dig deeper into Cyberhaven technology and how new types of analysis are being fueled by a new ultra-high-definition graph.
Building a New Source of Truth
There is a well-worn trope in movies and TV shows like NCIS, in which an investigator squints at a blurry surveillance image or video and utters the magic word…enhance. The view zooms multiple times, somehow becoming clearer in the process, and the all-important clue is revealed. This, of course, is not at all the way things work in the real world. While there are always inventive ways that we can reinterpret data or see it from another angle, eventually what we can know, and know conclusively, is constrained by the source data we have. It’s why scientists build evermore sensitive instruments and spend billions of dollars on things like the James Webb Telescope. If we are going to get better answers, we don’t just need more data, we need better data.
This is very true when it comes to security as well. While graph analysis of data flow can be a powerful tool, the analysis will always be constrained by the data that we have. So in order to protect data, we need an incredibly detailed and complete graph that captures and connects every movement or action performed on a piece of data. This can include every time a user edits a file, data is copy-pasted from one file to another, shared across applications, transformed from one format to another, and so on. In each case, exactly what data is being affected and to follow that no matter where it goes or how it is transformed.
For example, a user may copy/paste data about a particular customer account from a Salesforce.com browser tab to a Word doc. We need to be able to recognize that that particular document now has information about that particular customer account. This requires us to analyze and maintain deep context across virtually any application where data can be transmitted or modified. This could include everything from an end-user chat function on a social media application to backend API integrations between enterprise SaaS applications in the cloud.
Ultimately, what we are talking about is shifting from an event-based perspective to a flow-based perspective that encompasses all the complex interactions, movements, and relationships that actually define what data means to a business. There are two very important improvements that are needed in order to achieve this goal :
- Capture High-Resolution Details – First, we collect far more detail than the traditional “events” collected by say an EDR tool and far beyond that of a SIEM or UBA. For example, a user’s browser may have hundreds of network connections and process hundreds of files. It isn’t enough just to see that a browser interacted with a specific file. We need to know if it was actually uploaded and if so, which of the hundreds of network connections it was sent to. We would need to see “inside” the browser to know that a file was specifically sent to Box, and just as importantly, if it was sent to a user’s personal Box account or the corporate Box account. Likewise, we need to see and track virtually any user action on a device such as copying data into another file, renaming a file, encrypting a file, etc. And again, we need to track the flow of data for that specific action and not just see that a file was saved.
- Support Any Application Natively – Next, we need to be able to capture information and automatically trace the flow of data in virtually any off-the-shelf application without the need to modify the app itself. Previously, data lineage tools required making changes to each application, typically requiring work from the developers who built the application in the first place. However, if we want to truly protect enterprise data, we need to support all applications, such as browsers, office apps, email clients, collaboration tools, source code tools, as well as custom applications built by enterprises. Just as importantly, we need to support these applications in a lightweight way that doesn’t interfere with the application itself or require work from developers.
Combining Data Flows With Graph Analysis
These requirements were the driving factors behind a variety of Cyberhaven breakthroughs in the way that endpoint agents can track data lineage. And ultimately, all of this background work is designed to help us build a data set that can understand data flows and then perform graph-based analysis on those data flows.
Let’s look at how these two concepts fit together. Consider a user who receives a sensitive email, copies data from the email, pastes it into a Word document, and then uploads that document to Google Drive. In order to track this narrative, we need to retain the context of what window on the user’s machine the data was copied from. We need to be able to see that it was an email and know who that email was from. We need to record the copy action and connect it to the window where that content was pasted, which document was open in that window, and then track that document. We then need to track to see if the user then tries to share that file in any unapproved way such as uploading the file to a personal Google Drive.
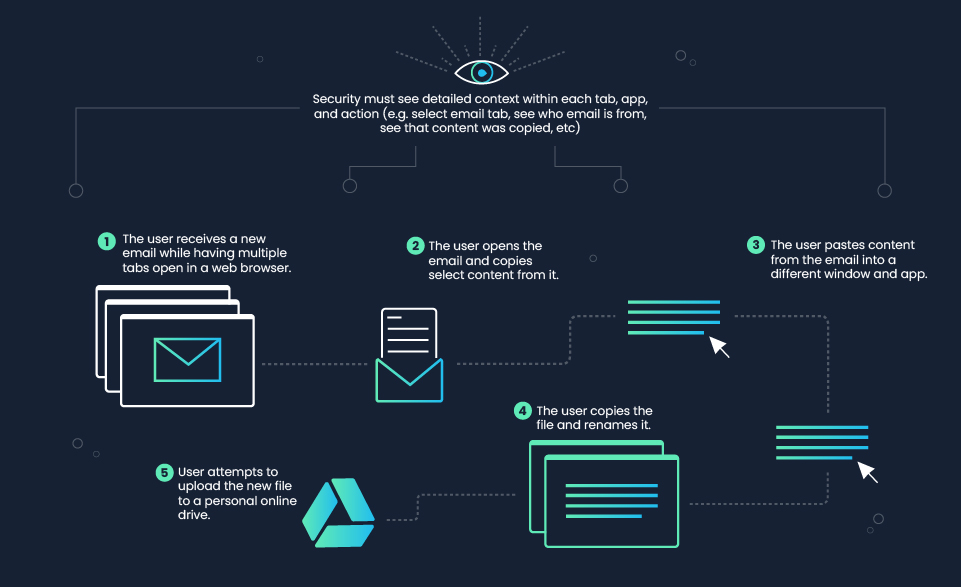
This is a relatively straightforward data flow. And understanding this flow is crucial to understanding what is really happening (or has happened) to a piece of data. Graph analysis allows us to “walk” or connect the dots across large numbers of these flows in order to get a true enterprise-wide context of the data and the data risk. Every day, a single user will perform dozens or even hundreds of similar actions. An enterprise will have hundreds of users, machines, and applications with data flows moving between (or within them). Data will exist over long periods of time, so we will need to be able to connect all of these data flows across all of these entities. The graph provides the superset of all this data so that we can pull the thread in any direction to get to the answers we need.
For instance, if we revisit the example of a user uploading a file to a personal Google Drive account, we may need to trace back the full lineage of that file to its origin to understand the risk. Maybe the content was downloaded from an HR app, then pasted into another document, and shared between multiple users. Graph analysis lets us connect all these flows to know in real-time that the data in question is sensitive and should be blocked from being uploaded to a personal account. On the other hand, let’s say we want to run the example in the other direction, and we want to know where all the copies of employee salary data are located within the company. In this case, we would walk all the many divergent branches of the graph in order to find every file, user, machine, or app that contains copies of that data.
Naturally, this requires graph analysis on a much larger scale than we have covered so far. In the next installment in the series, we will take a closer look at the challenges of analyzing this new type of graph at enterprise scale at very high speeds, and ultimately, all the important things you can do with it in your practice.