Introducing the Large Lineage Model (LLiM): Our path to securing the future of data

|
Updated:
June 3, 2025

Data security is about securing the secrets that belong to your organization. But it’s no secret that solutions like data loss prevention and insider risk management have barely evolved since their inception as on-premise applications designed to protect data from leaking outside the corporate perimeter. Cyberhaven was founded on the premise that there is a better way to do data security for hybrid organizations at the technological frontier that need better tools to provide uniform protection and visibility across the network, endpoint, and cloud.
Update: We're excited to share that Linea AI has evolved significantly with our Winter 2025 release, introducing groundbreaking capabilities that take data security to unprecedented levels. Our latest update includes enhanced content understanding through multi-modal analysis, a "Let Linea AI Decide" feature for incident prioritization, and new contextual policy recommendation tools. These innovations build upon the foundation of our Large Lineage Model (LLiM) technology, which remains at the core of how we combine data lineage with advanced AI to detect, investigate, and respond to data security incidents. As organizations face increasingly sophisticated threats to their sensitive data, the ability to understand not just what data is flowing but the context of those flows becomes critical—something only possible through the power of our lineage-based approach.
At the heart of our approach is a technology that we call data lineage, which enables teams to move beyond pattern matching and simplistic heuristics and instead focus on what is actually happening to data as it travels from endpoint to cloud and back. This powerful, high-accuracy method of data protection aggregates file events, metadata, and other relevant context about where data has traveled, who has accessed it, and how it has been modified. This information can automatically be surfaced regardless of the existing data classifications or policies in place.
What makes data lineage so robust is that it enables security teams to leverage context alongside content inspection during policy creation, enforcement, and investigation. This matters because content inspection alone is limited to how reliable specific regex patterns or detectors are, whereas context comprehensively captures how data is being handled. Our customers leverage data lineage to preview and understand the impacts of policy changes, create policies with highly relevant findings, and identify the true causes of incidents during investigation or triage.
Getting up to speed on data lineage
The purpose of data lineage is to create a unique history for each piece of data within your organization, which provides the context required to improve the accuracy of security policies, investigations, or business processes more generally. Because Cyberhaven leverages endpoint telemetry, browser plugins, and APIs to collect information on events related to data within your organization, this lineage is created regardless of whether the data is on the device or in the cloud.
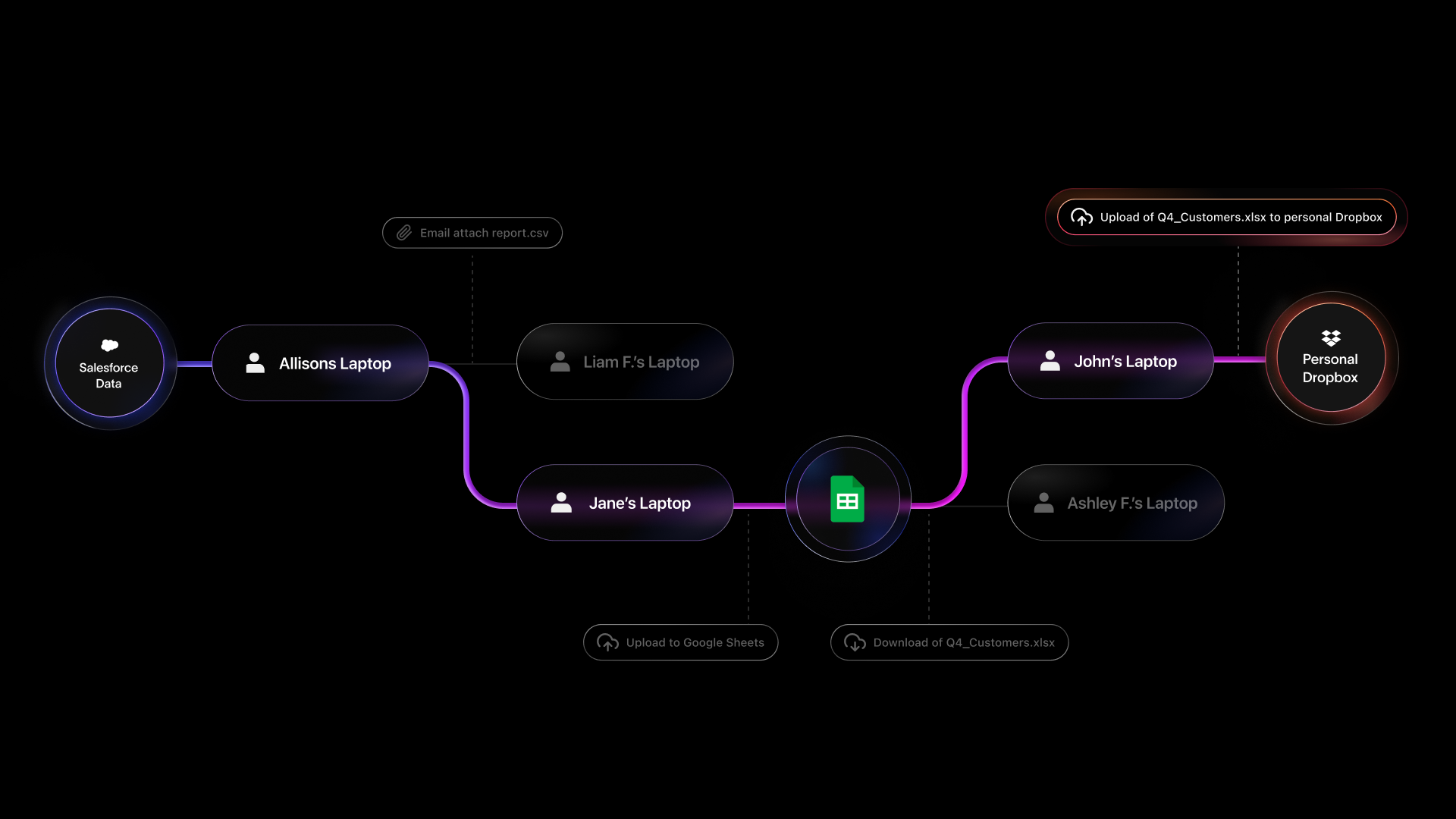
Data lineage provides persistent associations that can be used to uniquely identify not just files but individual snippets of data from files and other sources. All of these events are treated as signals to be aggregated and correlated in a graph database, which allows for the tracing of the journey a single piece of data takes throughout your entire organization. Cyberhaven generates data lineages in the cloud, ensuring no latency is introduced for end users on endpoints.
We have aggregated hundreds of billions of event signals into trillions of lineages over the course of Cyberhaven’s life, giving us a detailed understanding of data and business workflows that have allowed us to further tailor our product to our customers’ unique use cases.
Introducing the Large Lineage Model (LLiM)
We’ve always been interested in solving the most pressing issues in data security with the best available technology. We recognized that the power of data lineage could radically transform not just data security but the way that teams work. Individual data lineages reveal entire business processes, like what steps employees always take when developing a board presentation, how many collaborators the process requires, whether the process involves third-party contractors or services, and more. Security teams can, of course, use this information to determine when someone is egressing data to people or places where it doesn’t belong; however, the potential for data lineage is truly limitless. The goal of augmenting lineage with AI is to essentially have a hyper-vigilant analyst who can see every flow of every process and intelligently understand what is happening and why to surface these insights so that business processes—including data security—can be improved. This is work that no amount of human labor could ever hope to scale to, but is essential to deliver the level of relevance, precision, and accuracy we’re aiming for with data lineage.
Enter the large lineage model or LLiM. It’s a custom, in-house AI model trained on a huge collection of workflows that form our dataset to detect deviations in user behavior for a specific task or set of actions. As its name suggests, a large lineage model has been trained extensively on a massive number of data lineages to understand and ultimately reason about data flow and business processes. Our objective is to build on the technology on which our company was founded to realize the full potential of data lineage for our customers and partners. LLiM technology will form the foundation for shifting processes and culture by autonomously surfacing critical insights that can “10x” the entire organization, not just a single person or team.
How does a large lineage model work?
A large lineage model merges the intelligence breakthroughs enabled by the latest advancements in machine learning with a detailed understanding of business workflows enabled through data lineage. Leveraging datasets cultivated from our data lineage technology, our in-house model has developed a thorough understanding of business processes. Very broadly, our model works by understanding data workflows to create a conceptual model of how data is created and where it belongs. It has developed a robust way of reasoning about the difference between routine behaviors and data exfiltration and other behaviors creating security risks, as opposed to novel but ultimately safe ways of carrying out operational tasks.
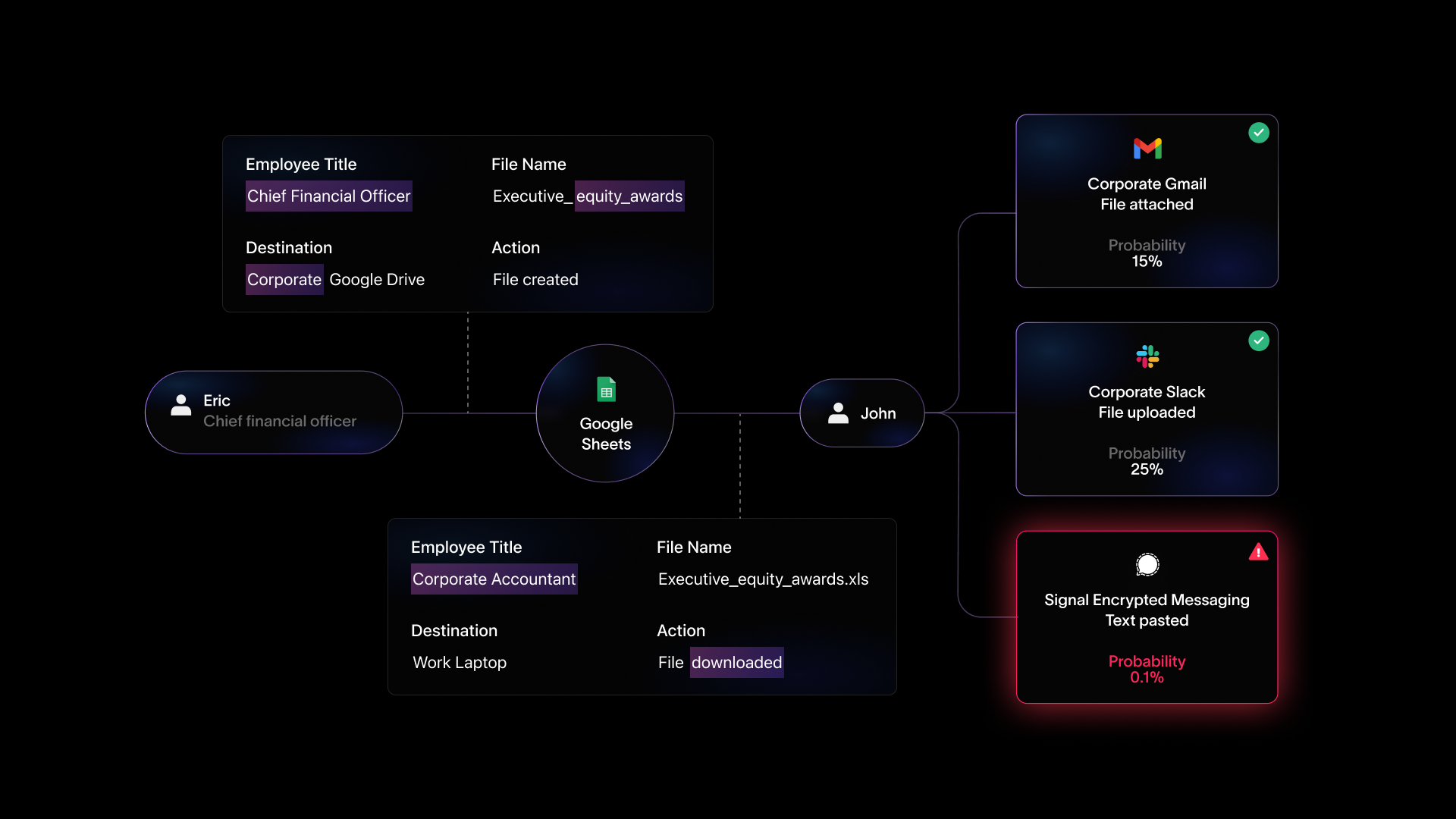
Training an LLiM is somewhat similar to an LLM, although, as we’ve alluded to earlier, lineage and not language is the core dataset used to train the model. The goal of training an LLiM is to use event signals to teach the model how to understand data workflows within the organization where it's deployed. This entails training the model to predict the next action within a workflow. Doing so enables the model to generalize more broadly about the applications in use within the organization, how to classify business-critical data in order to keep it safe, the locations where sensitive content should be stored, individuals with whom it makes sense to share data given their role, and much more. The model was trained through unsupervised learning on unlabeled data and then judged on its performance with a validation dataset that was created by having domain experts label events.
Our product, named Linea AI, consists of several modules, with the core component being the LLiM, which solely focuses on identifying risky behaviors via data lineage. Another key component is an explainer module, which employs a traditional LLM designed to take the outputs of the LLiM to grade the relative riskiness of incidents to help teams prioritize their response and create easy-to-read natural language explanations of the LLiM’s findings.
Practicing responsible development for safety and reliability
We take safety very seriously, given the size of the data we’re working with and the scale of our model. Building AI systems with safety in mind is not simply an ethical stance; it’s important because our partners require systems that perform reliably and with high accuracy.
Building systems this way starts before training. We made extensive efforts to anonymize the content in our dataset, removing identifiers like user names or other PII that might reveal or imply characteristics like gender, race, religion, etc. This cleaned dataset was the content used to train our model, using unique identifiers in place of personal information.
By design, the LLiM model is only trained on data events and not meant to interface directly with users, which limits opportunities for this subsystem to be introduced to new sources of bias or exploits that might coax this behavior. While Linea AI provides explanations through an LLM, the interfacing between the LLiM and LLM is limited and only occurs as needed when an anomaly is detected, with the amount of data shared being very minimal and strictly controlled. This limits the contexts where the model’s behavior can be influenced. The LLM was evaluated separately with the state-of-the-art safety practices used to secure today’s most popular LLMs. We are also starting a red teaming process for both models to stress test their behaviors. Within our evaluations, bias is something we explicitly tested to ensure that outputs precluded bias.
Building privacy-first AI systems
Privacy was also top of mind while developing Linea AI, enabling us to build a system that respects end-user privacy and is compliant with data privacy regulations. As part of our commitment to privacy, our systems only review contents when there is a strong probable cause of a policy violation, limiting the viewing of data to the minimum necessary to provide functionality. Additionally, our system does not take actions with any human impact without bringing human administrators into the loop for review.
Evolving beyond traditional detection methods
What sets Linea AI apart is its ability to go beyond the traditional pattern-based detection methods that have dominated the data security landscape for years. By combining our deep understanding of data lineage with advanced AI modeling, we've created a system that doesn't just identify isolated incidents but comprehends entire business workflows and their context. This contextual awareness means that Linea AI can distinguish between normal business operations and truly risky behavior with unprecedented accuracy. Our early adopters have reported dramatic reductions in false positives while simultaneously increasing detection rates for genuine data security risks. This shift from reactive to proactive security posture enables security teams to focus their attention on meaningful incidents rather than chasing statistical anomalies that don't represent actual threats. As organizations continue to expand their digital footprints and embrace more complex workflows spanning multiple applications and environments, this contextual intelligence becomes not just beneficial but essential to maintaining effective data security.
Looking forward to the future of data security!
While we’re happy to share details about the current state of Linea AI, we’re more excited about our product's future. This year alone, we’re going to be introducing dozens of features to continuously improve the utility of our AI-augmented features, including extra modalities like vision to improve the ways in which Linea AI can monitor and detect anomalies. Stay subscribed to our blog to stay up to date with the latest developments and announcements.



.avif)
.avif)
