←
Back to Blog
Platform architecture
1/16/2024
-
XX
Minute Read
Evaluating Security Agents and Their Impact on Endpoint User Productivity


Simultaneously addressing productivity, compatibility, configuration, and management is crucial in the realm of endpoint security agents. This article delves into the effects agents have on endpoint user productivity, a metric designed to measure the direct and indirect performance impact of security agents. Security tools, unlike other software, must integrate deeply with the operating system and third-party applications, which, when managed poorly, can impact the smooth flow of standard business operations. As a security solution vendor, our solution to this problem is to introduce the concept of an impact budget as well as impact safeguards.
How security tools impact user productivity
Productivity and security are often at odds with each other — generally, in order to improve one, you need to trade off the other. This is because security is enabled through additional checks that ensure specific criteria are met before a process is allowed to continue. As an everyday example, passing through airport security checks is a hassle because the security agents must ensure certain conditions are met before you can board a plane: they check that passengers are who they claim to be, are not carrying weapons or dangerous materials, etc.
For our use case, we define user productivity impact as the duration that a user's ability to perform a desired action on their endpoint was slowed or degraded. End users employ workstations to carry out their job responsibilities. Any auxiliary program, like a resource-hungry agent, that slows down or otherwise disrupts the software that the end user needs for those goals ultimately impacts the user’s productivity.
User productivity may be impacted directly and/or indirectly. Direct impact happens when a third-party program explicitly intercepts business software. For instance, antivirus software may intercept internet browsers in order to ensure that they do not download malware. Similarly, VPN software may intercept an email client in order to redirect and encrypt traffic. Indirect impact occurs when programs compete for limited shared resources. The classic example is CPU and memory usage — if many programs run on a computer with limited processor availability or memory resources, the computer will become sluggish.
Why endpoint agents are a challenging security product
Endpoint security agents can be a headache for IT departments. Agents may cause a large variety of issues that are hard to trace back directly to the agent. So much so that many vendors have now resorted to calling them sensors instead, as if changing a word changes reality.
For instance, users may complain about the internet browsing experience being slow when visiting certain websites. This can happen if a security agent performs extra checks on that website, but it can also be due to a myriad of other issues: bandwidth, VPN, ISP, server, hardware resources, firewall, etc. Even worse, the issue can be caused by a combination of factors, which makes the investigation and resolution even more complex.
This ambiguity often leads to a lot of time spent on troubleshooting and debugging before the problem can be finally addressed. An experience like this results in frustration for everybody involved: the end user, the IT department, and the vendor(s) of the offending software – and sometimes, vendors of unrelated products are unfortunately caught in the middle.
These challenges aren’t just limited to agents; however, operating systems pose a similar problem for organizations and developers. Because of the variety of environments in which OSs are deployed (hardware, software, configurations), there is a long tail of compatibility issues that may occur. Although these can be rare, they’re often unpredictable and complex to identify. Most major OS vendors have abandoned the idea of addressing this long tail in the lab during Quality Assurance; instead, they resort to a combination of early access releases and rich telemetry through open beta “canary” programs and “insider previews”.
What's the solution?
Cyberhaven systematically balances the security vs. productivity tradeoff. In this post, we’ll use the concept of user productivity impact budget and safeguards to describe how we solved this problem. We invite readers to take a look at our previous paper Inline and out of band approaches to protect data, which explains the architecture decisions that made this possible.
User productivity impact budget limits the amount of time that an endpoint user is unable to perform their desired task(s). Safeguards are activated when this budget is exceeded to manage the resource consumption of the agent. Safeguards addressing direct versus indirect productivity impact are implemented differently.
Safeguards addressing direct productivity impact will skip requests for integration points that exceed the impact budget. For example, if the impact budget is exceeded for file open verification, the security product has to stop checking file open activities for a configurable time window but keep logging all such activities.
Safeguards addressing indirect productivity impact will stop any security component or process that exceeds the allotted impact budget. For example, if memory consumption is limited to 800MB, when the security process exceeds this amount, it will be restarted by the OS (or some other monitoring component). It’s worth noting that restarts are also a type of action with its own safeguards defined – such as exponential backoff to prevent restart loops that consume system resources.
Addressing the problem of direct impact
In our security product, we are able to control and measure direct impact because there is a finite list of integration points that our software uses. We then reduce our presence to a minimal number of such integration points to manage the impact budget.
For each integration point, we measure the duration of each individual interaction with our component, as well as the sum total of time of all interactions involving one of our components during a particular time window.
As an example, below is a list of integration points for which the impact budget is defined and that we keep under control through safeguards:
- Microsoft Office add-in. Example of user-initiated actions: open email, save attachment, export document, print email
- Browser extension. Example of user-initiated actions: upload file, download file
- File System Driver on Windows/Endpoint Security Framework Component on Mac Example of user-initiated actions: open file, copy file, execute application
As explained earlier, the impact budget is defined both in terms of latency per integration point and cumulative processing time, both of which can be configured remotely.
For example, the direct impact budget for a file open action looks like this:
- Latency budget: single file open action must be verified within 1 second.
- Cumulative budget: total verification time of all file open actions over a 30-second interval must not exceed 15 seconds.
Addressing the problem of indirect impact
Indirect impact happens when the agent competes with a user action for a constrained system resource like memory usage or disk usage. If the resource is not close to exhaustion, there is no indirect user impact. This is because keeping the processor idle or memory free does not increase system performance. At the same time, long-term resource usage can lead to higher energy consumption and lower battery time. To account for this, we estimate energy usage based on absolute resource usage over a long period of time (such as 1 hour).
Below is a list of resource types for which an impact budget is defined and that we keep under control through safeguards:
- CPU usage: processor usage of our integration components as a relative percentage.
- Memory usage: Amount of memory used by our integration components that can’t be used by other processes (non-shared committed memory).
- Disk usage: Storage size in bytes (persistent storage).
- Network usage: Sent and received bytes over the network.
- Energy usage: Total processor usage by our agent across all cores in seconds.
How to evaluate performance safeguard options
Depending on an organization’s priorities, the failure of a security solution can be handled through either a fail-open or a fail-closed strategy. A fail-closed strategy blocks an action if the security solution can’t perform verification, whereas a fail-open strategy allows access in such a situation.
A fail-close strategy is effectively equivalent to having an unlimited impact budget, which is untenable for any enterprise solution. Customized safeguards are what allow us to implement fail-open strategies for each integration point or resource type, maximizing security without unreasonable expectations.
For example:
- If an action affected by a single integration point is exceeding the latency impact budget, its processing is stopped and the operation continues execution without further interaction with the integration point.
- If the sum total time of actions affected by a given integration point exceeds the time budget, future such actions of this type are no longer monitored by this integration point during the time window specified by the impact budget.
P99 telemetry is collected to assess the likelihood of safeguard activation for each integration point. This helps set reasonable defaults for the impact budget, balancing security with user productivity impact.
Example telemetry of CPU usage over time with P99 compared to P90, median, and average
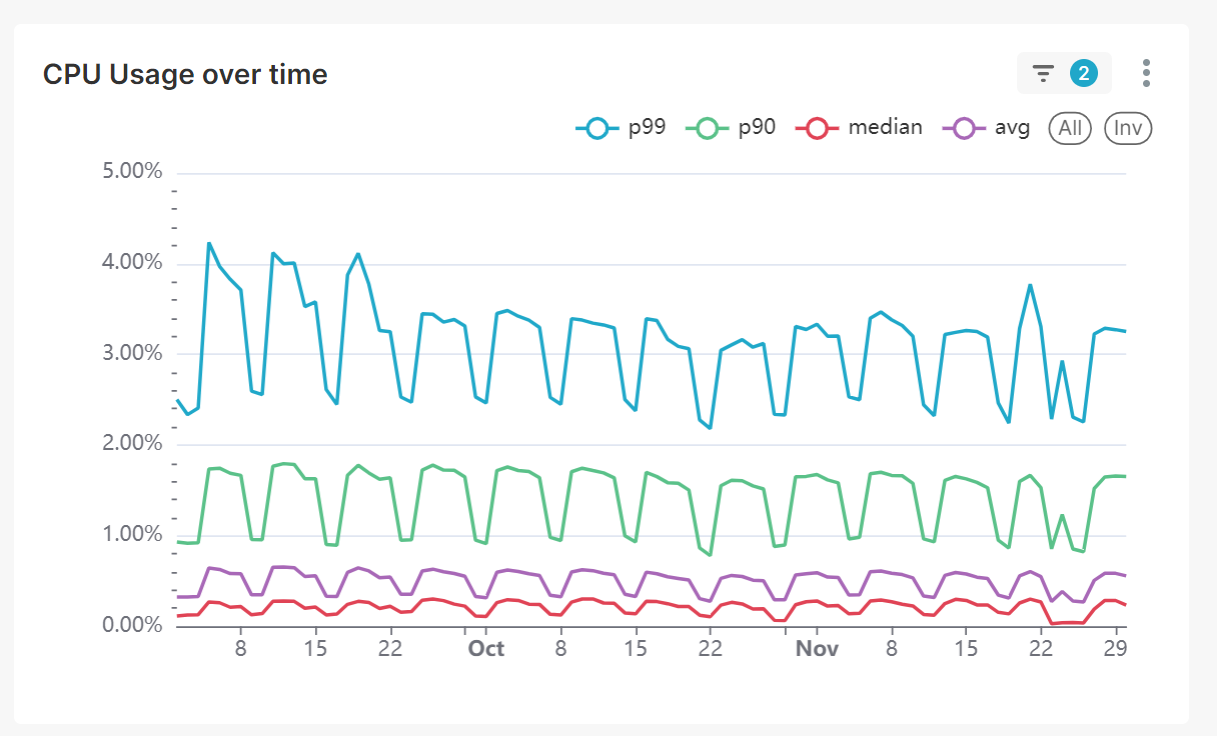
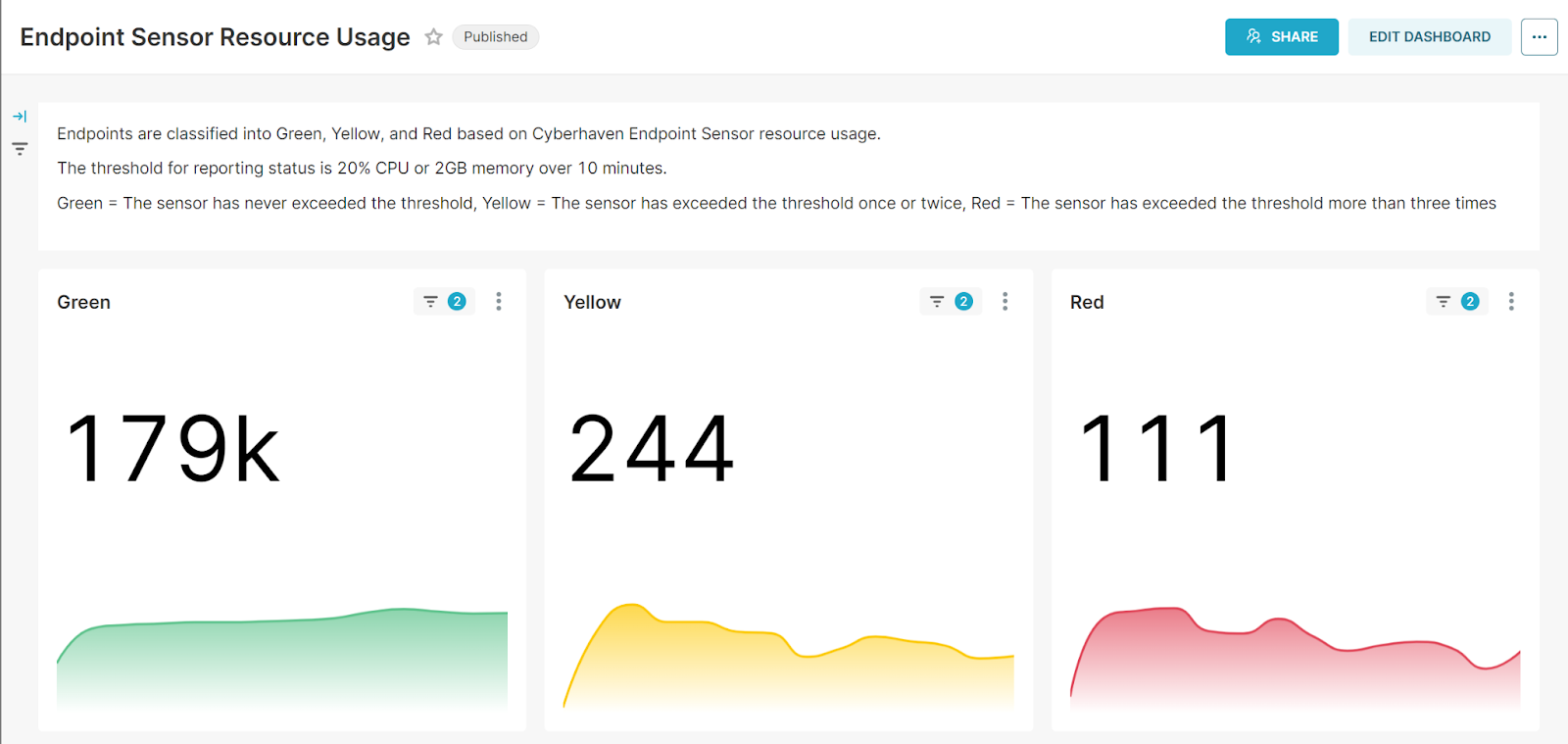
Furthermore, ongoing safeguard activation telemetry is collected from each endpoint to monitor the situation over time. For ease of monitoring, all endpoints are split into 3 groups based on safeguard activation and impact budget usage:
- An endpoint goes into the red bucket if the impact budget was exceeded more than three times a day.
- An endpoint goes into the yellow bucket if the impact budget was exceeded at least once.
- Otherwise the endpoint is marked as green.
How averages can hide information
When evaluating performance, many vendors may turn to using averages to illustrate what a user’s experience may look like at any given time. A lightweight agent is usually described by average resource consumption numbers, e.g. average CPU consumption is 0.5%. But it’s important to understand that averages often hide information.
For example, if we take the average CPU consumption of an agent, across all endpoints, then average it over 24 hours across 7 days (instead of measuring CPU consumption during active time, defined as when the user was performing actions), then divide this by the same average CPU consumption of all applications on the endpoint—there are high chances that the value will be close to zero, because most properly written security agents don’t actively scan or poll the system during idle time, nor do they constantly keep the CPU busy during generic user actions—they target specific actions with individual integration points.
So it’s not surprising that most security endpoint agents claim that they are very lightweight—yet cause severe user productivity impact in reality. There is a highly recommended article on this topic:
https://www.dynatrace.com/news/blog/why-averages-suck-and-percentiles-are-great/
Our approach fights this in several ways:
- By using absolute time in seconds for our user productivity impact budget.
- By using P99 telemetry-driven percentiles to estimate the probability of hitting an impact budget.
- By collecting per-endpoint telemetry to assess the productivity impact on a particular endpoint user.
- By grouping endpoints in red/yellow/green buckets to see time trends and correlate them with properties such as OS, agent version, etc.
Conclusion
Building an endpoint agent is a challenging exercise in software design that is hard to do right. Most agent-based solutions lead to endpoint user productivity impact and IT support tickets.
This leads to the reality that productivity and security are at odds with each other, even if most security companies won’t admit it. Instead of avoiding the word “agent”, or making unrealistic resource consumption promises, we use the concept of productivity impact budget, combined with safeguards to balance productivity and security tradeoffs.
The user productivity impact budget is defined as the amount of time that an endpoint user was unable to perform their desired action(s). When the impact budget is exceeded, safeguards are activated to keep productivity impact under control.
P99 telemetry is collected to assess the likelihood of safeguard activation for each integration point. This allows data-driven decisions on productivity vs security tradeoffs depending on an organization’s priorities.
Safeguard activation telemetry is collected from each endpoint to monitor the situation over time. This information allows customers to monitor and take suggested actions to resolve the productivity impact to endpoint users. Security providers and customers must be honest in accepting that realistically, on extremely resource-constrained systems where any productivity impact is unacceptable, this may include the need to upgrade hardware components, or to leverage allowlisting policies to reflect a more narrow attack surface.
“Nothing comes free. Nothing. Not even good, especially not good.”
Acknowledgments
We’d like to thank Alex Ionescu for numerous discussions on the topic presented here. Alex gave input on both the high-level flow of this essay as well as on small technical details and phrasing. This text would have been far less interesting without Alex’s help.
Thank you, Alex, for your continued support!